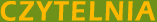
Bronisław Rocławski
Klasyfikacja artykulacyjno-akustyczna polskich głosek podstawowych z elementami wiedzy akustycznej.
Niech mottem do rozważań na temat artykulacji głosek będzie wypowiedź wybitnego znawcy sygnału mowy prof. dra hab. inż. Ryszarda Tadeusiewicza zawarta we Wprowadzeniu do książki Sygnał mowy (ISBN 83-206-0705-1): "Istnieją zjawiska, których złożoność przekracza wszelkie wyobrażenia, a które subiektywnie oceniamy jako pospolite i banalne. Dopiero bliższe zbadanie tych zjawisk, a w szczególności próba wykorzystania ich na gruncie techniki, uświadamiają, z jak bardzo skomplikowanym obiektem mamy do czynienia. Do zjawisk omawianej klasy należy m o w a. Doskonałość naturalnego systemu artykulacyjnego, jakim dysponują niemal wszyscy ludzie, powoduje powszechne wrażenie, że proces artykulacji jest łatwy, prosty, naturalny. Tymczasem w rzeczywistości język, wargi, struny głosowe wykonują tysiące ruchów precyzyjniejszych od manipulacji zegarmistrza i szybszych niż ewolucje akrobaty na trapezie."
Mowa składa się z dźwięków. Jerzy Regent w pracy Higiena głosu śpiewaczego (Gdańsk 1990) pisze: "Dźwięk jest to forma energii powstająca w wyniku zaburzenia ośrodka materialnego, np.: powietrza, wody, drewna itp., zdolna do wytworzenia wrażenia słuchowego. Zaburzenie to nosi również nazwę fali akustycznej. Każde zaburzenie rozchodzi się w ośrodku w postaci fali." Kiedy mówimy o fali, to najczęściej podajemy jej amplitudę w jednostkach zwanych decybelami (dB), częstotliwość w jednostkach zwanych herzami (Hz) czas trwania w ms i barwę. Amplituda to inaczej natężenie fali głosowej; z natężenia fali głosowej bierze się jej głośność, a ten parametr jest wyznaczany w związku ze słyszeniem dźwięku. Wyznacza się dla fali o częstotliwości 1000 Hz wartość progową (L = 0 dB) i szczytową (L = 120 dB). Należy pamiętać o nielinearności narządu słuchu, co objawia się tym, że przy ustalonym poziomie natężenia dźwięku L wrażenie głośności zmienia sie wraz z częstotliwością. Na tym polega tzw. subiektywne słyszenie. Największa czułość ucha na zmiany głośności występuje w zakresie częstotliwości od 1000 do 2000 Hz.
Z częstotliwością związane jest wrażenie wysokości dźwięku. J. Regen pisze: "Wysokości dźwięku złożonego nie daje się określić metodami obiektywnymi. Dlatego wysokość dźwięków muzycznych określa się w odniesieniu do częstotliwości podstawowej tego dźwięku." Jako częstotliwość odniesienia przyjęto wartość częstotliwości podstawowej dźwięku a1 (f = 440 Hz). Maksymalna rozdzielczość tonów wynosi ok. 3 Hz. Minimalny czas potrzebny do rozpoznania wysokości dźwięku wynosi ok. 4 ms dla C3."
Minimalny czas trwania dźwięku do poprawnego jego rozpoznania wynosi wynosi ok. 4 ms. Jeśli dźwięk trwa krócej, to jest odbierany jako trzask.
Czas potrzebny do rozpoznania barwy jest stosunkowo długi i wynosi 60 ms. Próg rozróżniania barwy ocenia się jako przesunięcie częstotliwości decydującego formantu o około pół tonu. O formantach mowa nieco dalej.
Klasyfikacja artykulacyjna głosek obejmuje klasyfikację samogłosek i spółgłosek. Artykulacja to inaczej sposób ułożenia i poruszania się narządów mowy. Samogłoski klasyfikujemy, odwołując się do wieloboku samogłoskowego, zwanego też czworobokiem samogłoskowym.Wielobok samogłoskowy jest figurą, która powstała w czasie wymawiania samogłosek w czterech skrajnych położeniach masy języka. Do oznaczania tych skrajnych położeń używamy wierzchołka grzbietu języka. Pierwszy punkt oznaczymy, gdy język i wierzchołek języka przeniesiemy w skrajne przednie i wysokie ułożenie. Teraz język będzie blisko podniebienia twardego (palatum). Obok są ilustracje pochodzące z pracy Handbook of the International Phonetic Association. A Guide to the Use of the International Phonetic Alphabet (ISBN 0 521 63751 1). Wierzchołek języka jest tu najwyżej. Wierzchołek grzbietu języka jest nieco niżej w skrajnym tylnym ułożeniu języka. Język lokuje się przy podniebieniu miękkim (velum). Teraz przenosimy się w skrajne niskie ułożenie najpier przednie. Stawiamy punkt. Jego postawienie umożliwia nam technika zwana rentgenografią. Kolejny punkt (czwarty i ostatni) postawimy po przesunięciu masy języka w skrajne dolne i tylne położenie. Z czterech rentgenogramów punkty przenosimy na jeden rentgenogram. Teraz możemy je połączyć. Powstał czworobok zwany wielobokiem samogłoskowym. Taka figura pojawia się (zob. obok) na liście znaków fonetycznych alfabetu międzynarodowego (IPA). W języku polskim jest sześć (6) podstawowych samogłosek ustnych i bardzo wiele wariantów pozycyjnych i fakultatywnych (indywidualnych). Zwykle skupiamy uwagę na głoskach podstawowych z klasy głosek stanowiących dany fonem. Fonem to klasa głosek funkcyjnie jednorodnych, których wymiana w wyrazach (morfemach) nie powoduje zmian znaczeniowych. O istnieniu wariantów wiedzą w zasadzie fonetycy, logopedzi i glottoterapeuci. Samogłoski różnią się barwą. Różnica barwy bierze się z różnic w budowie rezonatorów. Najczęściej mówimy o dwóch rezonatorach: przednim i tylnym. Ich wielkość wpływa na barwę głosu wytwarzanego przez wiązadła głosowe lub w inny sposób. Samogłoski podstawowe powstają z udziałem wiązadeł głosowych. Wiązadła głosowe muszą drgać w środowisku składającym się z małych cząseczek. Z takich cząsteczek składa się otaczające nas powietrze. Te cząsteczki wiązadła głosowe wprawiają w ruch drgający. Powstaje fala, która dzięki powietrzu może względnie swobodnie rozchodzić się kuliście w przestrzeni z prędkością ok. 340 m/sek. W wodzie są lepsze warunki do przenoszenia fali głosowej. Fala przemieszcza się z prędkością ok. 1450 m/sek. W ciałach stałych np. w granicie fala dźwiękowa przemieszcza się nawet z prędkością 6000 m/sek., w drewnie 4000 m/sek. Korek i guma nie są dobrymi przewodnikami fali dźwiękowej. Tu prędkość fali jest mała i wynosi ok. 60 m/sek. Fala dźwiękowa jest rodzajem fali akustycznej. Fala akustyczna jest przykładem podłużnej fali mechanicznej. Fala dźwiękowa wywołuje u człowieka wrażenia słuchowe. Takie wrażenia u nas powstają, gdy fala dźwiękowa ma częstotliwość drgań na sekundę wynoszącą od 16 do 20000 razy. Częstotliwość podaje się w herzach (Hz) na cześć niemieckiego odkrywcy fal elektromagnetycznych Heinricha Rudolfa Herza (1857-1894). Częstotliwości poniżej 20 Hz nazywa się infradźwiękami. Są one wytwarzane i słyszane przez słonie, wieloryby i krety. Są używane do komunikacji na duże odległości. Powstają m.in. w czasie grzmotu, trzęsienia ziemi. Rozchodzą się na wielkie odległości prawie bez utraty energii. Dźwięki powyżej 20 000 Hz nazywamy ultradźwiękami. Używane są przez niektóre zwierzęta (np.nietoperze, delfiny) do echolokacji. Psy i koty słyszą dźwięki do 50000 Hz (50 kHz). Bardzo często można spotkać w literaturze mieszanie zjawiska rozchodzenia się fali i przepływu powietrza. Fala może się rozchodzić w kierunku odwrotnym do wypływającego powietrza. Fala to przemieszcznie się energii (drgań), a nie cząsteczek powietrza. Gdy mówimy, to bardzo często do wytworzenia fali dźwiękowej używamy jako generatora przemieszczające się powietrze. Powietrze przemieszcza się, gdy mamy różnice ciśnień. Aby uruchomić wiązdła głosowe musimy podnieść ciśnienie pod wiązadłami. Nad wiązadłami ciśnienie jest mniejsze i dlatego dochodzi do rozwarcia wiązadeł i wyrównania ciśnień, Wiązadła siłą mięśni zostaną wtedy zsunięte. To zjawisko powtarza się z dużą prędkością. Powstaje ton podstawowy. Oto uśrednione zakresy częstotliwości tonu podstawowego dla głosów śpiewaczych (zob. Sygnał mowy, s. 17):
- bas od 80 Hz do 320 Hz,
- baryton od 100 Hz do 400 Hz,
- tenor od 120 Hz do 480 Hz,
- alt od 160 Hz do 640 Hz,
- mezzosopran od 200 Hz do 800 Hz,
- sopran od 240 Hz do 960 Hz.
Stanisław Klajman w przywołanej tu Higienie głosu śpiewaczego podaje wartości zbliżone:
- bas E - e1 (około 80 Hz do 326 Hz),
- baryton G - g1 (około 100 Hz do 390 Hz),
- tenor H - c2 (około 125 Hz do 512 Hz),
- alt e - e2 (około 160 Hz do 660 Hz),
- mezzosopran g - g2 (około 195 Hz do 775 Hz),
- sopran h - c3 (około 244 Hz do 1024 Hz).
Nieco inne wartości podają autorzy ongiś i zapewne jeszcze dzisiaj znakomitej pracy wydanej w Polsce 1967 r. pt. Świat dźwięków John R. Pierce i Edward E. David
- bas 38 - 60 Hz,
- baryton 70 - 512 Hz,
- tenor 96 - 640 Hz,
- alt 105 - 1280 Hz,
- mezzosopran 128 - 1280 Hz,
- sopran 128 - 1450 Hz.
Warto też przytoczyć z tej pracy opinię autorów na temat ludzkiego aparatu głosowego: "... ludzki aparat głosowy jest niezwykle doskonałym i wszechstronnym instrumentem, którym człowiek nauczył się posługiwać z zadziwiającą precyzją."
Nauczyciele śpiewu, jak i wszyscy, którzy podejmują się nauki śpiewu dzieci, powini pamiętać o wartościach skali głosu w różnym wieku dzieci podanych przez Paulsena (zob. w: Higiena głosu śpiewaczego, s. 126.). Dojrzewanie narządu głosowego związane jest przede wszystkim ze wzrostem kratni, ale zależy także od rozwoju całego organizmu. Wraz z wiekiem rozszerza się skala głosu dziecka. Niżej podaję powszechnie przyjęte parametry tych zmian:
do piątego roku życia skala głosu obejmuje kwartę do seksty (d1 - g1, b1 (h1), a więc w granicach od 293,7 Hz do 391,9 Hz (493,9 Hz,
w szóstym, siódmym roku życia skala głosu obejmuje oktawę (c1 - c2), a więc w granicach od 261,6 Hz do 523,2 Hz,
w ósmym roku życia dziecka skala głosu obejmuje już nonę (c1 - d2), a więc w granicach od 261,6 Hz do 587,4 Hz,
w dziewiątym roku życia obejmuje decymę (c1 - e2), a więc w granicach od 261,6 Hz do 659,2 Hz,
w dziesiątym roku życia dziecka skala głosu obejmuje undecymę (h/b - e2), a więc w granicach 246,9 Hz do 659,2 Hz
Patricia Shehan Campbell i Carol Scott-Kassner w pracy Music in Childhood (New York 1995) podają na s. 130 następujące zakresy skali głosu i tessitury dla dzieci w wieku od 6-12 lat (za: Peggy Zahner: Vocal Pedagogy and Appropriate Repertoire for Pre-Adolescent Children, link:http://www2.truman.edu/~ed27/eg_folio/Zahner/Reflections/Evidence/Crabb.Pre-AdVoice.PDF 26 sty 2012, 17:30). Tessitura to najintensywniej wykorzystywany zakres skali głosu. W poniższych danych najpierw jest wiek, potem skala, a na trzecim miejscu tessitura:
wiek 6-7: c1- c2, d1 - h1
wiek 7-8: h - d2, d1 - c2
wiek 8-9: b (hes) - es2, h - d2
wiek 9-10: a - e2, e1- d2
wiek 10-11: as - f2, d1- d2
wiek 11-12: g - g2, d1 - d2
Fala powstająca w wyniku drgania wiązadeł głosowych jest w rzeczywistości falą składającą się z wielu fal składowych. Są to składowe harmoniczne, które tworzą szereg: fo, 2fo, 3fo, 4fo, 5fo itd. Najniższa częstotliwość w tego rodzaju szeregach jest określana jako częstotliwość podstawowa. Mowa tu też o tonie podstawowym lub krtaniowym. Częstotliwość 2fo nazywana zaś jest drugą harmoniczną, a 3fo trzecią harmoniczną itd. Harmoniczne nazywane są także alikwotami. Stwórzmy widmo tonu krtaniowego. Posłużymy się tu współrzędnymi kartezjańskimi. Mamy oś odciętych X i oś rzędnych Y. Na osi X zaznaczymy częstotliwość w kHz (w kiloherzach), a na osi Y natężenie (poziom względny) w dB. Ponieważ operujemy wartościami dodatnimi, to wykres powstanie w pierwszej ćwiartce.Najwyższą wartość natężenia ma ton podstawowy (fo), który plasuje się jako pierwszy słupek. Przyjmiemy tu częstotliwość tonu podstawowego 32 Hz. Pierwsza składowa harmoniczna będzie miała wartość dwukrotnie wyższą, a więc 64 Hz. Jest to róźnica oktawy. Harmoniczne są tłumione z nachyleniem około 6 dB/oktawę. Jeśli ton podstawowy ma wartość 40 dB, to ta harmoniczna ma o 6 dB mniej, a więc 34 dB. Druga składowa harmoniczna ma częstotliwość 3 razy większą od tonu podstawowego, a więc 96 Hz. Trzecia składowa harmoniczna ma wartość 4x32Hz= 128 Hz. Mamy odległość kolejnej oktawy i o kolejne 6 dB mniejszą amplitudę. Czwarta składowa ma wartość 160 Hz. Piąta ma wartość 192 Hz. Szósta ma wartość 224 Hz. Siódma ma wartość 256 Hz. Mamy odległość trzeciej oktawy i o kolejne 6 dB mniejszą amplitudę. Tu wynosi ona 22 dB. Alikwot jest 16. Ostatnia ma tu wartość 512 Hz. Jest to odległość 4. oktawy, co każe nam odjąć 6 dB, aby otrzymać amplitudę wynoszącą 16 dB. Widmo tonu krtaniowego miałoby podobny wygląd. Zapewne większe byłyby wartości częstotliwości i może także wartości amplitud.
To dotyczy tonu krtaniowego, który z krtani rozpoczyna wędrówkę wzdłuż toru (przewodu) głosowego. Ten tor składa się z różnych rezonatorów, które wpływają na falę głosową powstałą w wyniku drgania strun (więzadeł) głosowych. Tor (przewód) głosowy ma różną długość u mężczyzn, kobiet i dzieci, stąd różnice w wytwarzanych przez nich dźwiękach s(tosunkowo łatwe do zidentyfikowania). Wytwarzane samogłoski są także łatwe do zidentyfikowania. Dzieje się tak dlatego, że stosunek częstotliwości rezonansowych przy wymawianiu danej samogłoski przez różne osoby w zasadzie jest taki sam. Gdy zmianie ulegną wartości częstotliwości rezonansowych i stosunki między częstotliwościami rezonansowymi, to będziemy mieli inne samogłoski.
Przewód głosowy możemy potraktować jako rurę, której kształt zależy od stopnia rozchylenia warg i umiejscowienia języka. Język na grzbiecie ma garb, który rozdziela tor głosowy na dwie wnęki - przednią i tylną. Tylna wnęka sięga od garbu aż do więzadeł głosowych. Stopień przewężenia wytwarzanego przez garb, jak i jego miejsce, wpływają na barwę samogłoski. Melville Bel oparł się na pozycji garbu języka i dokonał podziału samogłosek na przednie, środkowe i tylne. Stopień przewężenia stał się podstawą do podziału samogłosek na wysokie, średnie oraz niskie. W wieloboku na ryc. 3. strefa średnich artykulacji została podzielona na dwie. Międzynarodowe Stowarzyszenie Fonetyków wyróznia 4 strefy i wprowadza w układzie pionowym masy języka inne nazwy. Wyróżnia się głoski zamknięte (close), w połowie zamknięte (close-mid), w połowie otwarte (open-mid) i otwarte. Nie pasuje tu określenie samogłoski zamknięte, skoro o samogłoskach w ogóle mówi się jako o głoskach otwartych. Używane są też inne określenia dla samogłosek. Używa tych określeń W. Jassem w swoich pracach, m.in. w dwóch znakomitych książkach Podstawy fonetyki akustycznej (Warszawa 1973) i Mowa a nauka o łączności (Warszawa 1974). Jassem pisze o przymkniętych, półprzymkniętych, półotwartych i otwartych. Nazwa półotwarte w tradycji językoznawczej odnosi się do spółgłosek sonornych. Dla polskich samogłosek wysokich proponuję używać nazwy przymknięte. Przymkniętymi są głoski: i, y, u. Głoski e, o niech noszą nazwę średnie, a samogłoska a niech jest otwartą. Na ryc. 4., pochodzącym z mojej książki Podstawy wiedzy o języku polskim dla glottodydaktyków, pedagogów, psychologów i logopedów (Glottispol, Gdańsk 2005), znajduje się wielobok samogłoskowy z oznaczonymi samogłoskami podstawowymi (i y e a o u). Podaję też zależność między budową akustyczną, a budową artykulacyjną. W budowie akustycznej samogłosek główną rolę odgrywają częstotliwości formantowe. Są to częstotliwości składowych harmonicznych złożonej fali krtaniowej, których amplituda wzrosła w wyniku przejścia fali przez okreśony rezonator. Wyróżnia się rezonator tylny i przedni. Rozgranicza je przewężenie utworzone przez garb języka. Rezonator tylny to przede wszystkim jama gardłowa. O kształcie rezonatora przedniego decyduje miejsce położenia garbu grzbietu języka oraz ułożenie warg. Między położeniem garbu (wierzchołka) grzbietu języka a wargami istnieje korelacja. Mówimy tu o dwóch kompleksach artykulacyjnych: kompleksie delabialno-palatalnym i labio-welarnym. W kompleksie delabialno-palatalnym kąciki warg (labia) oddalają się w miarę, gdy język swą masą coraz bardziej zbliża się do podniebienia twardego (palatum). Widzimy to przy wymawianiu głoski e, a najwyraźniej przy wymawianiu głoski i. W kompleksie labio-welarnym kąciki warg zbliżają się do siebie, wargi są wysunięte i zaokrąglone. Język swą masą kieruje się w stronę podniebienia miękkiego (welum). Obserwujemy to przy głosce o, a najwyraźniej widzimy to w czasie wymawiania samogłoski u. Realizacja kompleksów wpływa na kształt rezonatorów. Rezonator tylny (gardłowy) wzmacnia niskie składowe harmoniczne. Ta grupa wzmocnionych przez niego tonów składowych otrzymała nazwę formantu pierwszego (F1). Rezonator przedni ma mniejszą objętość i w związku z tym wzmacnia wyższe składowe harmoniczne. Ta grupa wzocnionych przez rezonator przedni tonów otrzymała nazwę formantu drugiego (F2). Na ryc. 5. możemy śledzić zmiany w położeniu F1 i F2 w polskich samogłoskach podstawowych ustnych. Najniżej jest zaznaczony formant zerowy (Fo) związany z tonem podstawowym.
Na osobną uwagę zasługują polskie fonemy samogłoskowe zwane nosowymi. W rzeczywistości mamy do czynienia z fonemami realizowanymi głoskami ustno-nosowymi. Róźnią się one od samogłosek ustnych przede wszystkim strukturą dwusegmentową. Głoski podstawowe mają pierwszy segment ustno-nosowy przypominający nosową głoskę e i o. Ten segment możemy wyraźnie obserwować w czasie śpiewu. W śpiewie ulega wydłużeniu (do wartości nuty) pierwszy segment. Drugi segment w mowie i śpiewie trwa krótko i w obu głoskach przypomina unosowioną głoskę ł. Obie głoski są nietrwałymi głoskami właśnie ze względu na ten drugi segment. Wydłużanie w mowie (nie w śpiewie) głosek ę i ą powoduje zastępowanie ich grupą dwugłoskową, a w konsekwencji grupą dwufonemową. O wielu sprawach tu nie omawianych czytelnik przeczyta w Podstawach wiedzy o języku polskim dla ...
Niżej prezentuję tabelę z klasyfikacją artykulacyjną spółgłosek podstawowych. Ciekawą uwagę wypowiadają autorzy Świata dźwięków (s.113): Zachowanie się drugiego formantu, czyli centrum samogłoski, po lub przed jakąś spółgłoską stanowi podstawowe kryterium identyfikacji tej spółgłoski.